

2023年9月21日(現地時間)に、米OpenAIはChatGPTに新機能「DALL-E 3」を追加すると発表し、AI業界を驚かせました。
この「DALL-E 3」は、ユーザーが入力したテキストに基づいて、高解像度の画像をリアルタイムで生成する能力を持つ画像生成AIです。
これにより、ついにChatGPTで画像生成が可能となりました!
DALL·E 3🤝ChatGPT pic.twitter.com/90ITkUAln2
— OpenAI (@OpenAI) September 21, 2023
このChatGPTの新機能「DALL-E 3」は、10月初旬からChatGPT Plusおよび法人版「ChatGPT Enterprise」のユーザーに順次提供が開始される予定です。
しかしながら、「DALL-E 3」について具体的な機能や、その実際の使い方や活用方法、日本語での利用の有効性、商用利用や著作権の詳細について、あなたはどれだけ知っていますか?
そこでこの記事では、「DALL-E 3」の使い方や進化点、活用事例、日本語での使用方法、そして商用利用の際の注意点や著作権について、詳しく紹介していきます。
新しい技術の可能性を最大限に引き出すための情報が詰まっていますので、ぜひ最後までご一読ください。
この記事を読むことで、以下のメリットがあります。
- 「DALL-E 3」の使い方や、その圧倒的な画像生成能力を理解できる
- 実際に「DALL-E 3」でどんな画像が生成できるのか、日本語プロンプトは使えるのかなど、具体的な実用例でその力を確かめることができる
- 「DALL-E 3」で生成された画像の商用利用や著作権などについての詳しい情報を手に入れることができる
これらの内容をもとに、「DALL-E 3」を最大限に活用するためのヒントと知識をお伝えします。
是非、この記事を一読し、「DALL-E 3」の新たな可能性を共に探ってみましょう!

DALL-E 3(ダリ スリー)とは?
「DALL-E 3」の開発元は、ChatGPTと同じく米OpenAIです。「DALL-E 3」の読み方は、「ダリ スリー」です。
「DALL-E」から「DALL-E 2」、そして今回の「DALL-E 3」と続く「DALL-E」シリーズは、OpenAIによって2021年1月に初めて発表された、画像生成AIの一つです。
この「DALL-E」シリーズが一般に大きな影響を与えたのは、テキストから画像を生成することが可能である点です。この機能は、デジタルアートから科学的研究まで多岐にわたる用途に使われています。
DALL-E 3では、その前世代である「DALL-E 2」から大きく進化しており、より高精細でリアルな画像をテキストから生成できます。
「DALL-E 3」の進化のポイント:高解像度とテキスト理解力の飛躍
「DALL-E 2」からの進化として目を引くのが、生成される画像の解像度の大幅な向上です。
「DALL-E 2」では一定の解像度に限定されていましたが、DALL-E 3では高解像度で緻密な画像を生成可能になりました。
さらに、複雑なテキストに対しても、その意味やニュアンスをしっかりと捉え、忠実な画像生成が可能になっています。
下の図は、同じプロンプトで生成された、「DALL-E 2」と「DALL-E 3」の図の比較です。
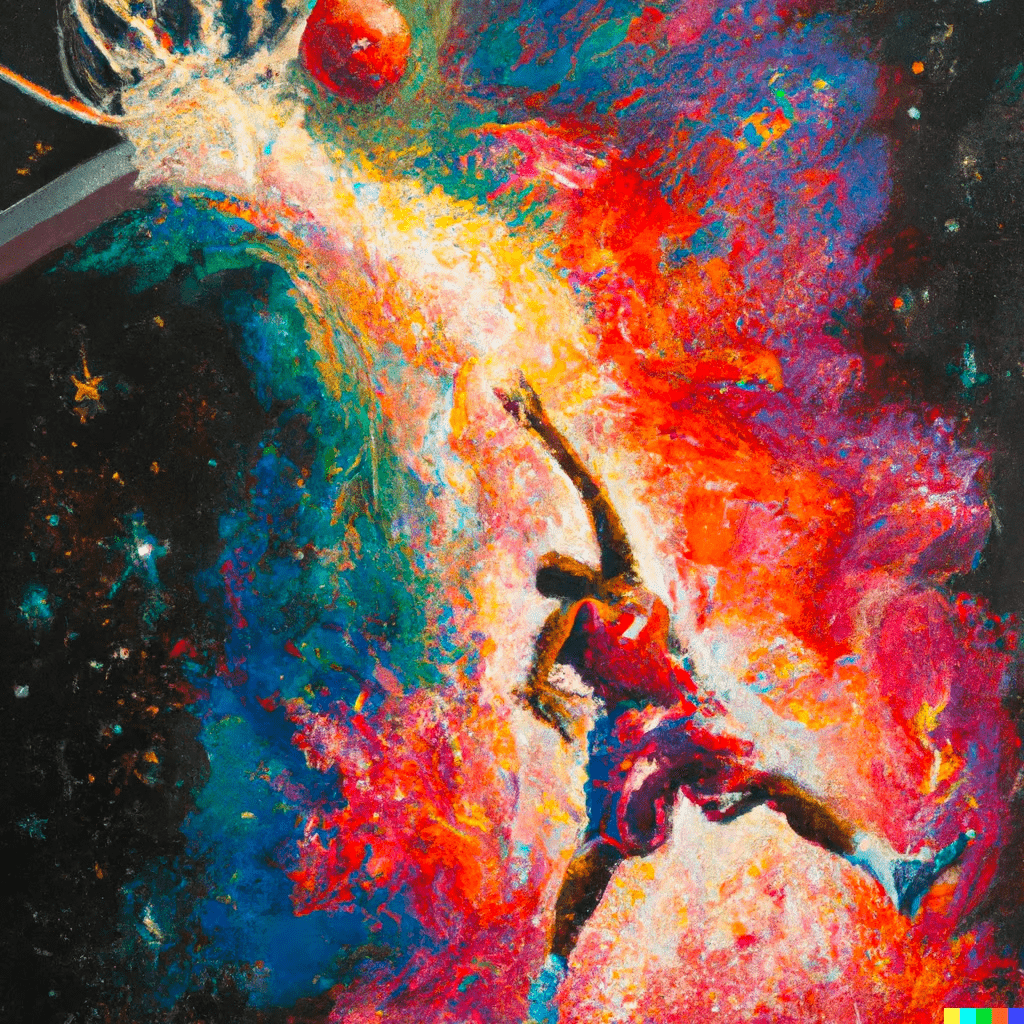
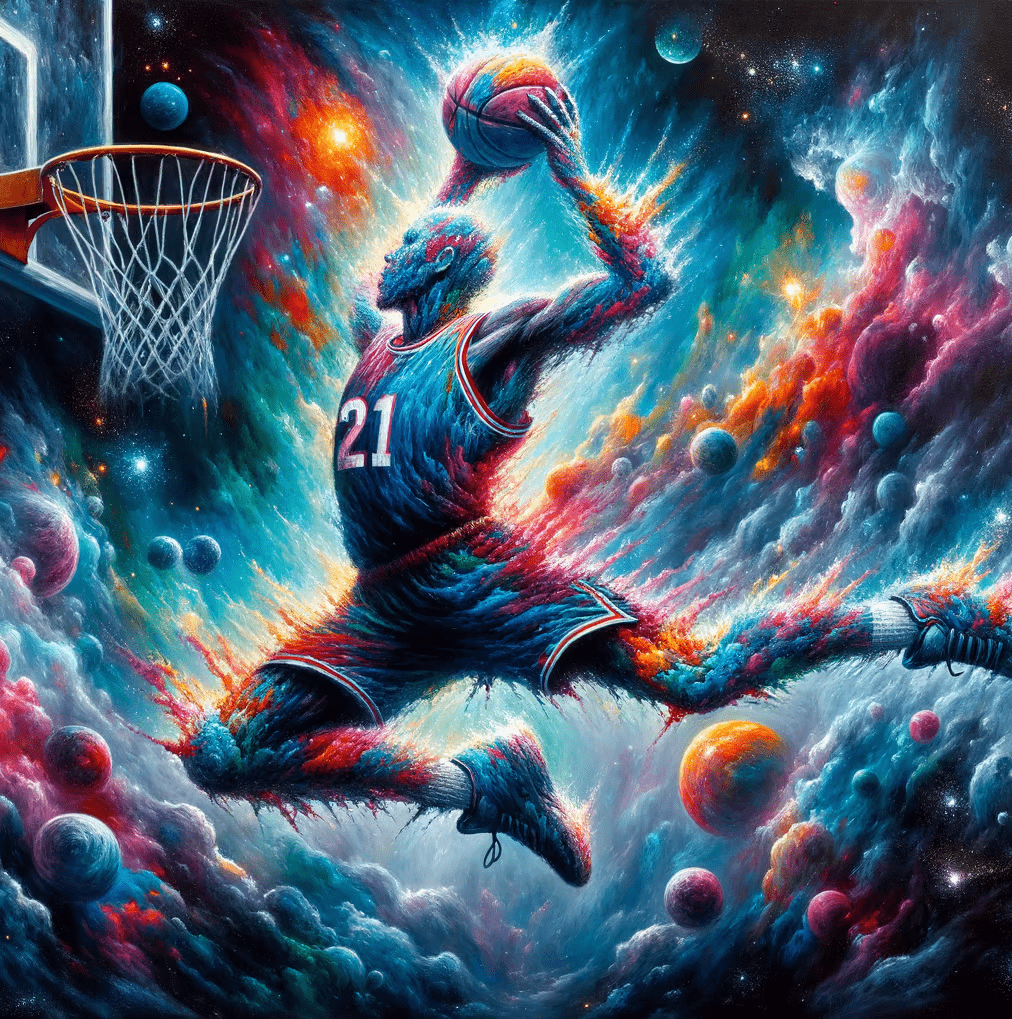
「DALL-E 2」と「DALL-E 3」の生成画像の能力の差は一目瞭然です。
「DALL-E 2」の生成画像と比較して、「DALL-E 3」による画像は、より鮮明でディテールが豊かになりました。色彩のバランスや物体の輪郭、シャドウの表現も進化しています。
例えば、上記のプロンプトである「星雲の爆発のように描かれた、バスケットボール選手がダンクを決める表情豊かな油絵」を元に生成された画像を見ると、「DALL-E 2」では、ある程度の表現はできていましたが、「DALL-E 3」では、星雲の爆発の細部や選手の表情、動きのエネルギーまでが非常に緻密に再現されています。
テキスト忠実度が高い理由:「DALL-E 3」の認識アルゴリズム

「DALL-E 3」は、入力されるテキストに非常に高い忠実度で画像を生成できるのが一つの大きな特長です。
たとえば、「夜空に輝く満月」よりも、「夜空に輝く満月とその周りを飛ぶ3匹のコウモリ」といった複雑なテキストでも、そのニュアンスを理解し、対応する画像を生成できます。
この高いテキスト忠実度は、「DALL-E 3」の高度な認識アルゴリズムによるものです。
ChatGPTでの「DALL-E 3」の使い方
DALL-E 3は10月初旬から、ChatGPT Plusおよび法人版「ChatGPT Enterprise」のユーザーに順次提供される予定です。
「DALL-E 3」の使い方は簡単です。
ChatGPTにログイン後、下の図のように「DALL-E 3」を選択するだけで利用を開始できます。
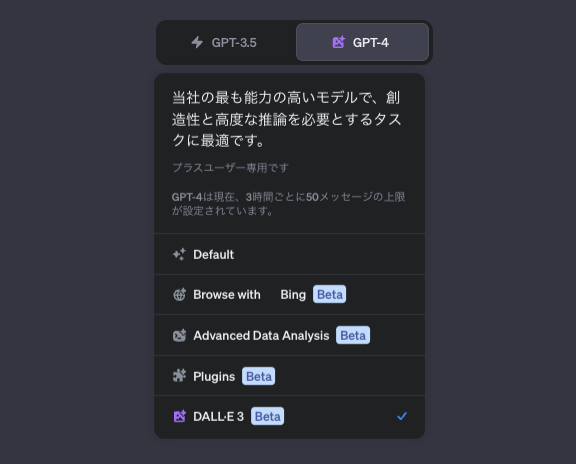
プロンプトを入力すると、下の画面のように「DALL-E 3」が画像作成を始めます。4つの画像のプロンプトを自動で考えてくれることに驚きです。
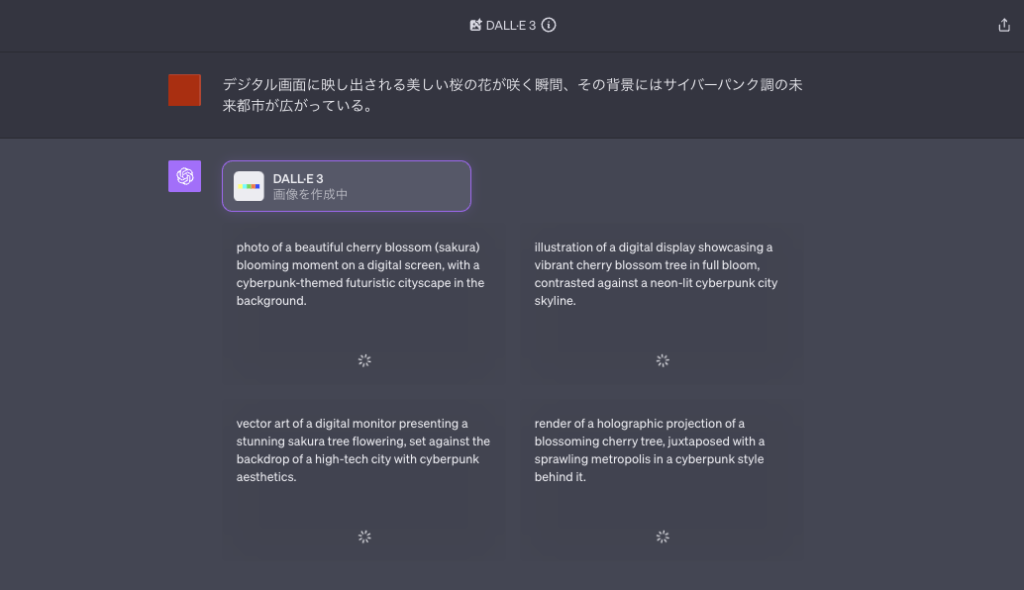
「DALL-E 3」が4枚の画像を生成しました。完成まで1分もかかりませんでした。

「DALL-E 3」で生成される画像は商用利用可能
「DALL-E 3」で生成される画像は、商用利用も許可されています。これにより、マーケティング資料や広告など、ビジネスシーンでの利用範囲も大きく拡がります。
【10/28追記】生成される画像が4枚から2枚に変更
日本時間2023年10月28日頃から、「DALL-E 3」で生成される画像が4枚から2枚に変更になりました。

OpenAIからの正式な発表はありませんが、負荷対策による仕様変更だと考えられます。
【11/9追記】生成される画像が2枚から1枚に変更
「DALL-E 3」で生成される画像が2枚から1枚に変更になりました。

OpenAIからの正式な発表はありませんが、負荷対策による仕様変更だと考えられます。
【11/10追記】「OpenAI DevDay」後のアップデートで、ChatGPTのUIが大幅変更
ChatGPTを開発する米OpenAIが、開発者向けの初のカンファレンス「OpenAI DevDay」をサンフランシスコで2023年11月6日10時(日本時間11月7日午前3時) に開催しました。
「OpenAI DevDay」では、「GPT-4 Turbo」や「GPTs」、「GPT Builder」、「GPT Store」、新APIなど、驚きの新機能などが発表されました。
「OpenAI DevDay」についてはこちらの記事に詳しく解説しています。

「OpenAI DevDay」後に、ChatGPTがアップデートされ、UI(ユーザーインターフェース)が大きく変更されました。
アップデート前のUIは、下の画面でした。
「OpenAI DevDay」後のアップデートで、以下のUIに変更されました。画面は「ChatGPT 4」を選択した様子です。
2.png)
「GPT-4」の中に、「DALL-E 3」のほか「Browsing」「Advanced Data Analysis」が統合され、非常にシンプルになりました。
今後は、「GPT-4(ChatGPT 4)」を選択するだけで「DALL-E 3」が使用できます。
OpenAIの「DALL-E 3」実用例:公式サイトから選りすぐりの7事例を紹介
それでは、実際に「DALL-E 3」がどれほど進化しているのか一緒に見ていきましょう!
この記事では、OpenAI公式サイトで紹介されている「DALL-E 3」による生成画像をプロンプトと共に7つご紹介します。
それぞれの画像は、一体どのようなプロンプトによって生み出されたのでしょうか。さぁ、この先端技術がいかに我々の想像力を超えているのか、一緒に探って行きましょう。
例①「DALL-E 3」で生成した画像:最上階のペントハウス

この画像は「DALL-E 3」によって、以下のプロンプトで生成されました。
A silhouette of a grand piano overlooking a dusky cityscape viewed from a top-floor penthouse, rendered in the bold and vivid style of a vintage travel poster.
この「DALL-E 3」によって生成された画像は、まさに美術品のよう。プロンプトの細やかな指定に忠実に、かつ独自の解釈を加えて描写された都市の夜景とピアノのシルエットは、ヴィンテージの旅行ポスターの雰囲気を感じさせます。
この一枚から、技術の進化だけでなく、AIが持つ芸術的な可能性を強く感じ取ることができます。
例②「DALL-E 3」で生成した画像:アジア系の中年女性

この画像は「DALL-E 3」によって、以下のプロンプトで生成されました。
A middle-aged woman of Asian descent, her dark hair streaked with silver, appears fractured and splintered, intricately embedded within a sea of broken porcelain. The porcelain glistens with splatter paint patterns in a harmonious blend of glossy and matte blues, greens, oranges, and reds, capturing her dance in a surreal juxtaposition of movement and stillness. Her skin tone, a light hue like the porcelain, adds an almost mystical quality to her form.
「DALL-E 3」によって生成されたこの画像は、詩的で幻想的な美しさを持っています。アジア系中年女性の破片のような姿と、カラフルなスプラッター・ペイントの模様を持つ磁器の海が絶妙に融合しています。
特に彼女の淡い肌色と磁器との調和は、神秘的な印象を強く与え、静寂と動き、実際と幻想の間の境界をぼやけさせる効果があります。
これは、AIの技術の進化だけでなく、感情や想像力を刺激する作品の創出能力を示しています。
例③「DALL-E 3」で生成した画像:ヴィンテージの金星旅行ポスター

この画像は「DALL-E 3」によって、以下のプロンプトで生成されました。
A vintage travel poster for Venus in portrait orientation. The scene portrays the thick, yellowish clouds of Venus with a silhouette of a vintage rocket ship approaching. Mysterious shapes hint at mountains and valleys below the clouds. The bottom text reads, ‘Explore Venus: Beauty Behind the Mist’. The color scheme consists of golds, yellows, and soft oranges, evoking a sense of wonder.
「DALL-E 3」によって生成されたこのヴィンテージの金星旅行ポスターは、黄色い雲とロケット船のシルエットで冒険心をくすぐります。
魅力的なゴールドとオレンジの配色が、未知の宇宙探求の興奮を伝えます。霧越しの美しさが心を引きつける名作です。
例④「DALL-E 3」で生成した画像:対照的な2つの世界を隔てるトラ

この画像は「DALL-E 3」によって、以下のプロンプトで生成されました。
A stylized portrait-oriented depiction where a tiger serves as the dividing line between two contrasting worlds. To the left, fiery reds and oranges dominate as flames consume trees. To the right, a rejuvenated forest flourishes with fresh green foliage. The tiger, depicted with exaggerated and artistic features, stands tall and undeterred, symbolizing nature’s enduring spirit amidst chaos and rebirth.
「DALL-E 3」によって生成された画像は、火のような赤とオレンジの混沌と新緑の再生を虎が力強く隔てる独特のアートです。
この虎は、試練を乗り越える自然の不屈の力を美しく表現しています。
例⑤「DALL-E 3」で生成した画像:多様なモンスターの家族

この画像は「DALL-E 3」によって、以下のプロンプトで生成されました。
Illustration in flat design style of a diverse family of monsters. The group includes a furry brown monster, a sleek black monster with antennas, a spotted green monster, and a tiny polka-dotted monster, all interacting in a playful environment.
「DALL-E 3」によって生成された画像は、異なる特徴を持つモンスターたちが楽しげに交流する姿が鮮やかに描かれています。
このイラストは、家族の絆や多様性の美しさをユニークな角度から表現している感じがします。
例⑥「DALL-E 3」で生成した画像:ヤドカリのクローズアップ写真

この画像は「DALL-E 3」によって、以下のプロンプトで生成されました。
Close-up photograph of a hermit crab nestled in wet sand, with sea foam nearby and the details of its shell and texture of the sand accentuated.
「DALL-E 3」が生成したこの画像は、ヤドカリの繊細なディテールと砂の質感が鮮明に表現され、自然の美しさと生命の息吹を感じさせます。
海の泡が近くにあることで、海辺の静かな瞬間を捉えているようです。
例⑦「DALL-E 3」で生成した画像:崖の上に建つモダンな建築の建物

この画像は「DALL-E 3」によって、以下のプロンプトで生成されました。
A modern architectural building with large glass windows, situated on a cliff overlooking a serene ocean at sunset.
「DALL-E 3」が生成したこの画像は、崖の上に聳え立つモダンな建築の美しさと壮大な自然との融合を見事に表現しています。
夕暮れの静けさと建物の先進的なデザインが相まって、静寂と未来の共存を感じさせる風景となっています。
「DALL-E 3」の多面的な表現力
以上、OpenAIの公式サイトからピックアップした7つの事例を通じて、「DALL-E 3」が持つ表現力の豊かさをご紹介しました。
このAIは単なる技術的進歲以上のものを持っており、アートからビジネスまで多くの分野で革新が期待されます。特に注目すべきは、プロンプト一つ一つに対する繊細な解釈と表現力です。
さて、次のセクションでは、僕が独自に作成したプロンプトで「DALL-E 3」がどのような画像を生成するのか、興味深い事例をいくつかご紹介します。
【検証】日本語で「DALL-E 3」を使ってみた!
OpenAIの公式サイトで紹介されている「DALL-E 3」が生成した画像には、驚くべきものが数多くありました。しかし、これまでの例は全て英語プロンプトによるものです。
画像生成AIの分野においては、多くのAIが主に英語のプロンプトに最適化されているのが一般的です。このため、他の言語、特に日本語での画像生成が難しい場合が多いのが現状です。
例えば、専門的な言葉や独特な言い回しを取り入れた画像生成AI「Midjourney(ミッドジャーニー)」を使用する際のプロンプトの複雑さは一段と増します。
その高度な複雑さに対応するため、簡易的な日本語のプロンプトを入力するだけで、「Midjourney」向けの高度な英語プロンプトを自動生成してくれるChatGPTのプラグイン「Photorealistic」も登場しています。
「Photorealistic」プラグインについてはこちらの記事に詳しく解説しています。

このように多くのAI技術では英語のプロンプトが主流ですが、ところが、この「DALL-E 3」では日本語のプロンプトが使用可能です!
この背景を踏まえ、日本語のプロンプトによる「DALL-E 3」の実力を検証します。
日本語特有のニュアンスや言い回しで、どのような独自の画像が生成されるのか、興味深くご覧ください。
例①日本語で「DALL-E 3」が生成した画像:自然とテクノロジーの融合




この画像は「DALL-E 3」によって、以下のプロンプトで生成されました。
なお、画像をクリックすると、下の画面のように実際に使われたプロンプトが確認できます。

実際に使われたプロンプトを確認すると、以下のように元のプロンプトが「DALL-E 3」によってカスタマイズされていることがわかります。
①photo of a beautiful cherry blossom (sakura) blooming moment on a digital screen, with a cyberpunk-themed futuristic cityscape in the background.
他の3枚のプロンプトは以下のとおりです。
② illustration of a digital display showcasing a vibrant cherry blossom tree in full bloom, contrasted against a neon-lit cyberpunk city skyline.
③ vector art of a digital monitor presenting a stunning sakura tree flowering, set against the backdrop of a high-tech city with cyberpunk aesthetics.
④ render of a holographic projection of a blossoming cherry tree, juxtaposed with a sprawling metropolis in a cyberpunk style behind it.
例②日本語で「DALL-E 3」が生成した画像:和風アートと西洋アートの融合




この画像は「DALL-E 3」によって、以下のプロンプトで生成されました。
例③日本語で「DALL-E 3」が生成した画像:超現実的な日常




この画像は「DALL-E 3」によって、以下のプロンプトで生成されました。
例④日本語で「DALL-E 3」が生成した画像:歴史と未来の交錯




この画像は「DALL-E 3」によって、以下のプロンプトで生成されました。
例⑤日本語で「DALL-E 3」が生成した画像:東京の日常




この画像は「DALL-E 3」によって、以下のプロンプトで生成されました。
生成された画像を修正する方法
「DALL-E 3」で生成された画像を日本語で修正することもできます。
特定の画像を修正する方法
特定の画像を修正してもらいたい場合は、以下のように何枚目の画像をどうしてほしいかをプロンプトに書くと実行してくれます。
画像が何枚目にあたるかは、下の図を参考にしてください。

一枚目の画像をアニメ風にしてもらいます。以下のプロンプトを出してみました。

見事にアニメ風になりました。
アスペクト比(画像サイズ)を変更する方法
「DALL-E 3」では、現在、以下の三つの画像サイズを指定することができます。
- 正方形 (1024×1024)
- 横長 (1792×1024)
- 縦長 (1024×1792)
横長の画像を、正方形に変えてもらいます。以下のプロンプトを出してみました。

正方形で、画像が生成されました。
画像の一部を修正する方法
画像の一部やディテールを修正することができます。例えば、桜の花をひまわりにしてもらいます。
以下のプロンプトを出してみました。

いきなり人物(女の子)が描かれたので、実際に「DALL-E 3」で使われたプロンプトを確認してみました。
anime-style illustration of a digital screen displaying a beautiful sunflower, with a cyberpunk-themed futuristic city sprawling in the background.
プロンプトには人物(女の子)は書かれてませんが、おそらく「ひまわり」と「アニメ風のイラスト」ということから、アニメ風の女の子が描かれたようです。
そこで、人物を消してもらうために、以下のプロンプトを出してみました。

人物が消えて、希望の「桜の花をひまわりに変える」画像が生成されました。
【検証結果】「DALL-E 3」と日本語プロンプト、その驚異的な相性!
実際に日本語のプロンプトを使用して「DALL-E 3」の生成性能を検証してみたところ、その結果は予想をはるかに超えるものでした。
その圧倒的な画像生成能力と、日本語との素晴らしい相性に、驚かされました。以下に具体的な感想をまとめます。
- 精度の向上: 「DALL-E 3」は日本語のプロンプトにも高い精度で反応し、ユーザーの要求に合わせた画像を迅速に生成することができました。
- 文化的ニュアンスの捉え方: 日本の文化や風景に関連するプロンプトに対しても、適切な画像を出力することが確認されました。
- 多様性: 一つのプロンプトに対しても、さまざまな角度やスタイルでの画像を生成する能力が「DALL-E 3」には備わっているようです。
- 使いやすさ: 日本語のプロンプトでも簡単に操作でき、手間なく希望の画像を取得することができました。
この検証を通じて、「DALL-E 3」は日本語のプロンプトにも強く、幅広い用途での利用が期待できることが確認されました。
今後もさらなる機能の向上や、より多様な日本語プロンプトに対する対応が進むことで、利用の幅はさらに広がっていくことでしょう!
「DALL-E 3」で、「画像認識」機能によるテキストから画像生成してみた!
「DALL-E 3」と、米OpenAIが2023年9月25日(現地時間)に発表したChatGPTの注目の新機能「画像認識」とを組み合わせることで、さらなる可能性が広がると考え、検証を行ってみました。
ChatGPTの新機能「画像認識」についてはこちらの記事に詳しく解説しています。

今回の検証の目的は、「画像認識」機能で分析したテキストが、どれほど「DALL-E 3」によって忠実に画像として再現されるのかを確認することです。
その結果が非常に驚きのものであったので、ぜひ最後までご覧ください。
「画像認識」機能を使用し、画像の内容をテキストで詳細に解説
まずは「画像認識」機能を使用して、特定の画像の内容を詳しく解析し、その結果をテキスト形式で出力しました。
この機能の魅力は、画像の内容をどれほど詳しく、そして正確に言語化することができるのか、という点にあります。
実際に解析した画像は以下の画像。これはOpenAI公式サイトで紹介されている「DALL-E 3」による生成画像です。
画像を解析する具体的な方法は以下の通りです。
ChatGPTの画面にある、ファイルのアイコンをクリックして画像を添付します。

以下のプロンプト(命令文)を入力します。

結果として、上の図のように、「画像認識」機能により詳細に言語化されました。
「DALL-E 3」を用いて、解析されたテキストから画像を再生成
次に、この解析結果として得られたテキストを元に、「DALL-E 3」を用いて新しい画像を生成するステップを行います。
ChatGPTで「DALL-E 3」を選択します。
そして、以下のプロンプト(命令文)を入力しました。
「DALL-E 3」で生成された画像がこちらです。




画像は、衝撃的な美しさとなりました。
画像のサイズの指定がテキストにはなかったので横長になりましたが、画像の品質や再現性は非常に高いものとなっています。
生成された画像の中には、オリジナルの雰囲気が魅力的に表現されており、特に最後の画像はオリジナルに非常に近いタッチを持っていると感じました。
「DALL-E 3」と新機能「画像認識」を使用したこの検証の結果は、期待をはるかに超えるものでした。
【11/1追記】新機能「All Tools」で、アップロードした画像を元に「DALL-E 3」で画像生成が可能に!
先ほど、ChatGPTの「画像認識」機能を使って画像をテキスト化し、そのテキストから「DALL-E 3」で画像生成する実験を行いました。
しかし、日本時間2023年10月29日頃、ChatGPT(GPT-4)がさらなる進化を遂げ、操作が一層簡単になりました。
このアップデートで登場したのは、ChatGPTの「All Tools」という新機能です。
「All Tools」とは、一言でいうとChatGPTの全機能を切り替えなしで、一つのチャット内で行えるというものです。
これにより、「リアルタイム検索」「文書や画像のアップロードからの分析」「グラフ作成」「画像生成」などが連続して行えるようになりました。
特に画像生成の「DALL-E 3」において、テキストだけでなく、アップロードした画像を元に新しい画像を生成することが可能になりました。
ChatGPTの新機能「All Tools」についてはこちらの記事に詳しく解説しています。

「All Tools」と「DALL-E 3」を使って、画像の再現性を実験してみた結果は?
今回はこの新機能「All Tools」を使い、再度、OpenAI公式サイトで紹介されている「DALL-E 3」の生成画像を用いて実験を行いました。
上の画像をアップロードして、以下のプロンプト(命令文)を入力しました。
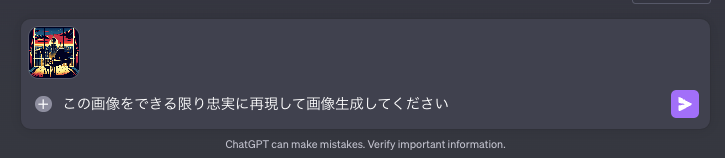
「DALL-E 3」で生成された画像がこちらです。


このように結果は驚くべきものであり、色彩や構図、雰囲気までもが忠実に再現されました。
先ほどの画像をテキスト化して「DALL-E 3」で画像生成した実験結果(下図)と比較してみると、今回の「All Tools」を使った方が明らかに画像の再現性が高いことがわかります。

生成された画像の一部を編集してみた結果は?
次に、生成された画像の一部を編集してみたいと思います。
以下のプロンプト(命令文)を入力しました。
「DALL-E 3」で生成された画像がこちらです。
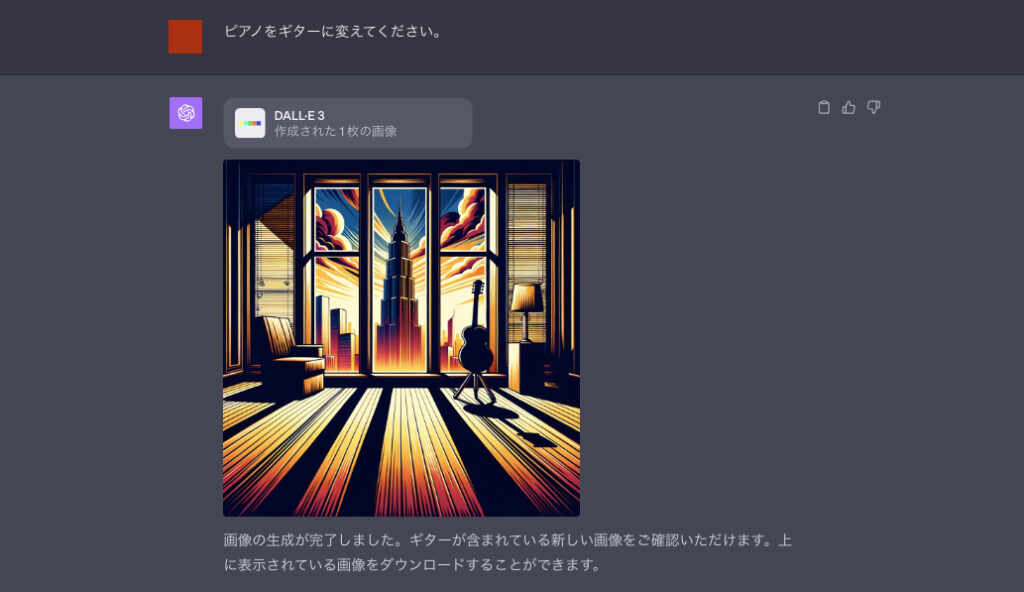
色彩や構図、雰囲気はそのままで、指示通りピアノがギターに変更されました。

ChatGPTがここまで来たのかという驚きでいっぱいです。
このように、今回のChatGPTのアップデート「All Tools」により、ChatGPTと「DALL-E 3」の連携が一層深まり、更にパワフルかつ効率的な画像生成が可能となりました。これからのさらなる進化にも期待が高まりますね!
【11/5追記】「DALL-E 3」で、パラメーターを使って画像生成をカスタマイズ!
Alvaro Cintas氏のツイートで、「DALL-E 3」のパラメーターの使用方法について紹介しています。プロンプトにパラメーターを追加することで、画像生成のカスタマイズが可能になります。
You can now use parameters in DALL•E 3!
— Alvaro Cintas (@dr_cintas) October 27, 2023
Parameters are options added at the end of a prompt that change how an image generates.
For example, “—ar 1:1” means that your image will have a square aspect ratio.
Here is what I wrote in my Custom Instructions for this:
“When using… pic.twitter.com/65WIoVCWxl
パラメーターとは?
パラメーターとは、プロンプトの末尾に追加するオプションのことです。例えば、「—ar 1:1」というパラメーターを使えば、生成される画像は正方形のアスペクト比を持つことになります。
パラメータを設定することにより、自分のニーズやプロジェクトの要件に合わせて、出力される画像の形式を細かく制御できるようになります。
「DALL-E 3」で利用できる主要なパラメーター
以下に、「DALL-E 3」で利用できるいくつかのパラメーターとその値をご紹介します。
「DALL-E 3」で利用できる主要なパラメーター
—ar(アスペクト比): このパラメーターを使用して、画像の縦横比を指定できます。「1:1」は正方形、「7:4」はワイド画面、「4:7」は縦長画面を意味します。—stylize(スタイライズ)または—s: 芸術的な色彩、構成、形式を重視するパラメーターです。低いスタイライズ値では、プロンプトに忠実ながら芸術性の低い画像が生成されます。高いスタイライズ値では、プロンプトから離れた非常に芸術的な画像が生成されます。値の範囲は0(最低)から1000(最高)です。—weird(奇妙さ)または—w: 画像のユニークさ、非現実性の度合いのパラメーターです。この値が高いほど、画像は奇妙になります。0(通常)から1000(最も奇妙)までの範囲があります。
プロンプトの終わりに「—」(エムダッシュ)または「–」(ダブルハイフン)と共に追加することができます。
パラメーターを使って「DALL-E 3」で画像生成をカスタマイズした結果は?
それでは、パラメーターを使って、「DALL-E 3」で画像生成をカスタマイズしてみたいと思います。
以下の4つのパターンで実験します。
—ar(アスペクト比)を「1:1」の正方形、—stylize(スタイライズ)を0、—weird(奇妙さ)を0—ar(アスペクト比)を「1:1」の正方形、—stylize(スタイライズ)を1000、—weird(奇妙さ)を0—ar(アスペクト比)を「1:1」の正方形、—stylize(スタイライズ)を0、—weird(奇妙さ)を1000—ar(アスペクト比)を「1:1」の正方形、—stylize(スタイライズ)を1000、—weird(奇妙さ)を1000
実験①—ar(アスペクト比)を「1:1」の正方形、—stylize(スタイライズ)を0、—weird(奇妙さ)を0
まずは、[—ar(アスペクト比)を「1:1」の正方形、—stylize(スタイライズ)を0、—weird(奇妙さ)を0」で画像生成の実験を行います。
以下のプロンプト(命令文)を入力しました。
「DALL-E 3」で生成された画像がこちらです。


パラメーターどおり、見事なコアラの正方形の画像を生成してくれました。
実験②—ar(アスペクト比)を「1:1」の正方形、—stylize(スタイライズ)を1000、—weird(奇妙さ)を0
次に、stylize(スタイライズ)を1000にして、[—ar(アスペクト比)を「1:1」の正方形、—stylize(スタイライズ)を0、—weird(奇妙さ)を0」で画像生成の実験を行います。
以下のプロンプト(命令文)を入力しました。
「DALL-E 3」で生成された画像がこちらです。


stylize(スタイライズ)を最大値にした結果、以前の検証①で得られた画像と比較して、はるかにアーティスティックな画像が生成されました。
実験③—ar(アスペクト比)を「1:1」の正方形、—stylize(スタイライズ)を0、—weird(奇妙さ)を1000
次に、weird(奇妙さ)を1000にして、[—ar(アスペクト比)を「1:1」の正方形、—stylize(スタイライズ)を0、—weird(奇妙さ)を1000」で画像生成の実験を行います。
以下のプロンプト(命令文)を入力しました。
「DALL-E 3」で生成された画像がこちらです。


weird(奇妙さ)を極限まで高めた結果、通常とは一線を画す、非常にユニークで目を引く画像が生成されました。
実験④—ar(アスペクト比)を「1:1」の正方形、—stylize(スタイライズ)を1000、—weird(奇妙さ)を1000
最後に、stylize(スタイライズ)とweird(奇妙さ)を共に1000にして、[—ar(アスペクト比)を「1:1」の正方形、—stylize(スタイライズ)を1000、—weird(奇妙さ)を1000」で画像生成の実験を行います。
以下のプロンプト(命令文)を入力しました。
「DALL-E 3」で生成された画像がこちらです。


stylize(スタイライズ)とweird(奇妙さ)の両パラメーターを限界まで押し上げたことで、想像を超える創造性あふれる、驚くべき画像が生成されました。
これは、「DALL-E 3」の画像生成能力がもたらす新たな可能性を示す一例と言えるでしょう。
注意点:「Midjourney」とは機能が異なります
これらのパラメーターは「Midjourney」のようには機能しません。
「Midjourney」はユーザーが直接的な指示を与えることで、その指示に応じた画像を生成します。
しかし、「DALL-E 3」の場合、パラメーターはGPT-4によってプロンプト自体が変更されるため、画像生成のアプローチが異なります。
例えば、「weird」パラメーターを最大限に設定して「最も奇妙な画像」を生成したい場合、「Midjourney」ではユーザーが直接その指示を入力しますが、「DALL-E 3」ではGPT-4がユーザーの指示を解釈し、それに基づいてプロンプトを変更して最適な結果を生み出します。
【11/5追記】「DALL-E 3」で生成された画像に、固有のID「gen_id」が付与される機能が追加!
ChatGPTの「DALL-E 3」機能が進化し、新たに画像に固有のID「gen_id」を付与する機能が追加されました。
この機能により、ユーザーは以前に生成した画像に簡単にアクセスできるようになり、画像の改善に関するフィードバックを同一スレッド内で行うことができます。
「DALL-E 3」生成画像に固有のID「gen_id」が付与
- 固有のID「gen_id」の導入: 「DALL-E 3」で生成された各画像には、固有のIDが割り当てられます。
- IDの簡単取得: ChatGPTに対して「gen_id」を問い合わせることで、生成画像のIDを取得できます。
- スレッド内の有効性: 取得した「gen_id」は、そのスレッド内でのみ有効です。
- 画像の参照と改善の容易さ:「gen_id」を活用して、以前の画像を正確に参照し、改善のためのフィードバックをスムーズに実施できます。
生成画像のID「gen_id」の取得方法
「gen_id」の取得方法は非常にシンプルです。
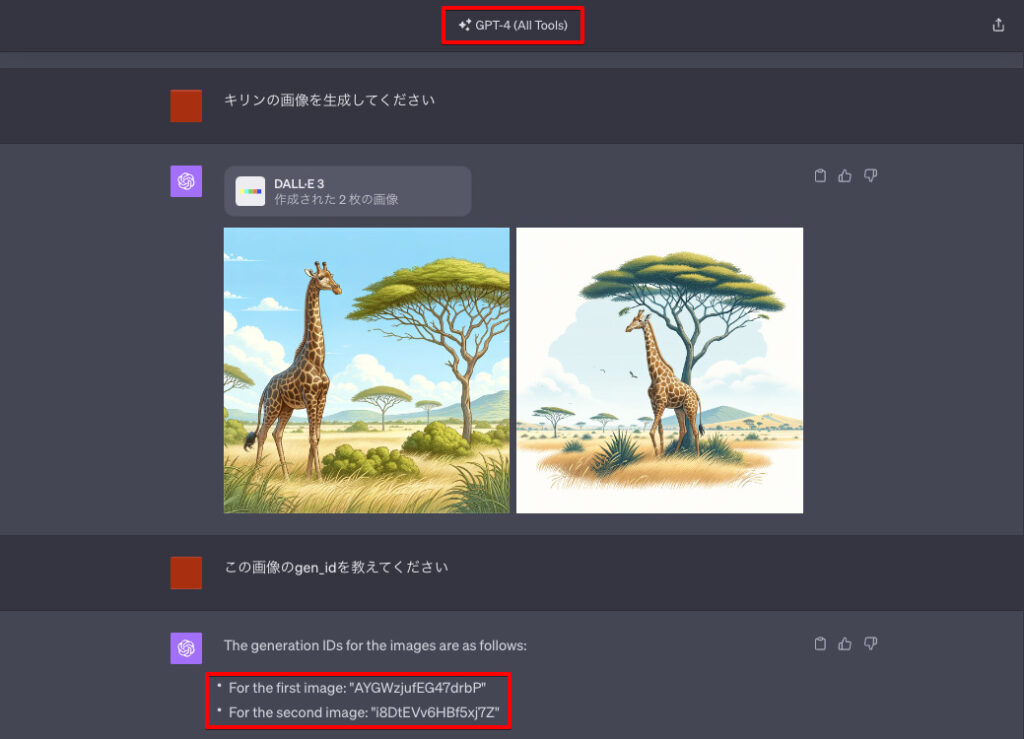
生成された画像の「gen_id」を知りたい場合は、以下のプロンプト(命令文)のようにChatGPTに質問するだけで、そのIDを取得できます。
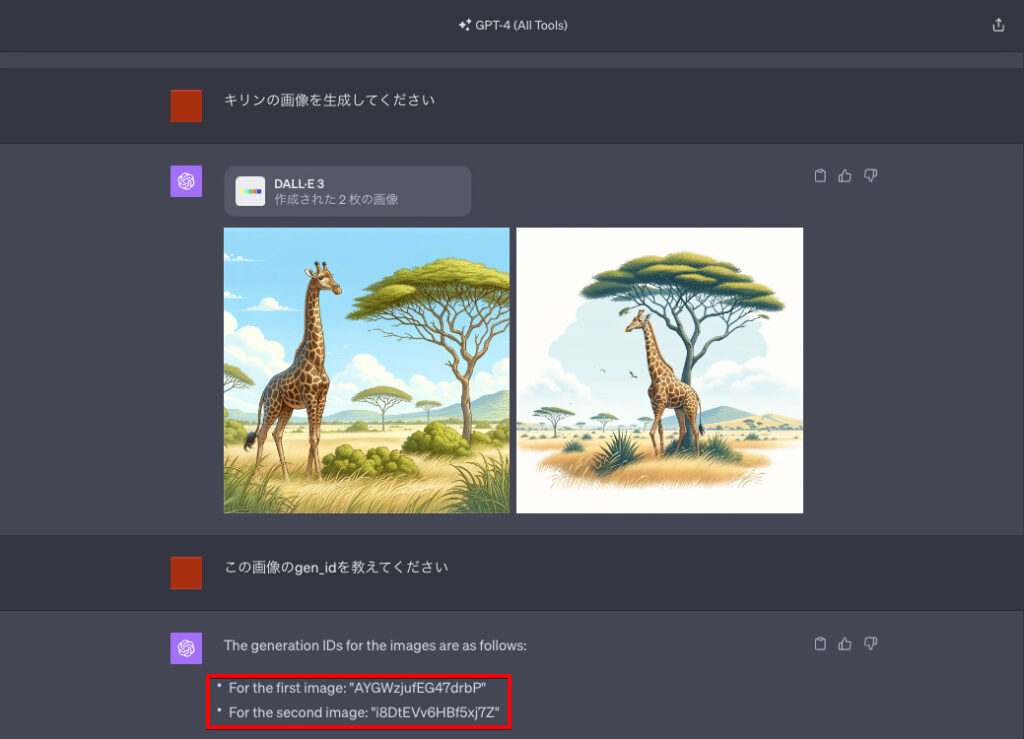
ChatGPTの回答をそのまま紹介します。
The generation IDs for the images are as follows:
・For the first image: “AYGWzjufEG47drbP”
・For the second image: “i8DtEVv6HBf5xj7Z”
このように、2枚の画像の「gen_id」をそれぞれ教えてくれました。
注意点:ID「gen_id」が取得できるのは「All Tools」使用時のみ
生成画像の固有ID「gen_id」が取得できるのは、上で紹介したChatGPT新機能「All Tools」使用時(Defaultモード)のみのようです。
下が、実際に「DALL-E 3」モードで生成した画像の「gen_id」を聞いた画像です。
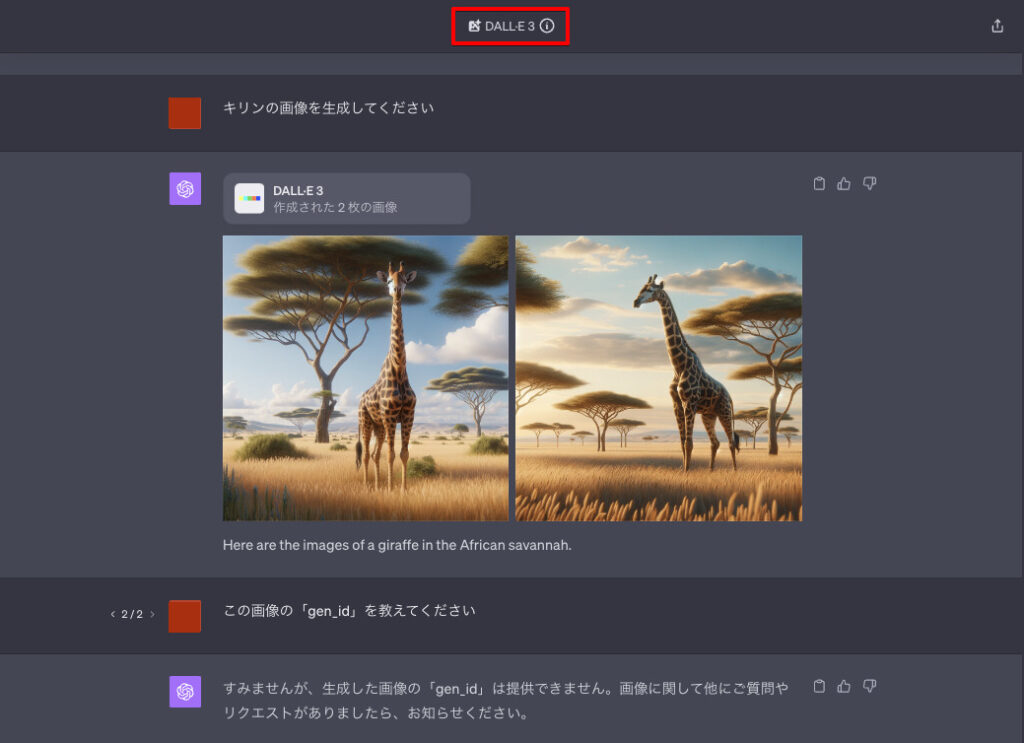
何度聞いても、ChatGPTは「gen_id」を答えてくれませんでした。
すみませんが、生成した画像の「gen_id」は提供できません。画像に関して他にご質問やリクエストがありましたら、お知らせください。
生成画像の固有ID「gen_id」が必要な場合は、必ず「All Tools」(Defaultモード)を使用されることをおすすめします。
ChatGPTの新機能「All Tools」についてはこちらの記事に詳しく解説しています。
【11/10追記】「GPT-4」のままで、ID「gen_id」が取得可能になりました!
2023年11月6日に開催された「OpenAI DevDay」後のアップデートで、下の画面のように「All Tools」が「GPT-4」の中に統合されました。
そのため、「GPT-4」のままでID「gen_id」が取得可能になりました。
「OpenAI DevDay」についてはこちらの記事に詳しく解説しています。
ID「gen_id」を使って、画像をカスタマイズしてみた結果は?
「gen_id」を指定することで、画像のカスタマイズが簡単になります。
さらに、スタイルの統一が可能になり、例えばシリーズ物のイラスト制作において、キャラクターや画風の一貫性を保つことが簡単になります。
「gen_id」の使い方はとても直感的で、「gen_id」を指定してChatGPTに指示を出すだけです。
例えば、先に「DALL-E 3」で生成した下のキリンの画像に対して変更を加えてみます。

この画像のキリンを2頭に増やすリクエストを行うために、以下のプロンプト(命令文)を出してみました。
「DALL-E 3」で生成された画像がこちらです。

結果、プロンプトどおり、キリンが2頭に編集された画像が生成されました。
では次に、同じスタイルを維持しながら、キリンをゾウに変更する実験をしました。
以下のプロンプト(命令文)を出してみました。
「DALL-E 3」で生成された画像がこちらです。

プロンプトに基づき、「DALL-E 3」はスタイルを保ったゾウの画像を生成しました。
このように「gen_id」を利用すれば、一度定めたスタイルを維持しつつ、画像の内容を変更するなどのカスタマイズが実現できます。
この機能は特にシリーズ制作において画風の統一が求められる際に有用で、創造性と効率性を兼ね備えた重宝するツールと言えるでしょう。
「DALL-E 3」と「Midjourney」の生成画像を比較してみた!
AI技術の進化により、私たちは非常にリアルな生成画像を見ることができるようになりました。
そこで、今回新たに登場したChatGPTの「DALL-E 3」と、先進的なAI画像生成ツール「Midjourney」を用いて、同じプロンプトで生成された画像の比較を行います。
具体的には、「自然に囲まれた女性のフォトリアルな画像」をテーマに、それぞれのツールがどのような画像を生み出すのかを確認しました。
以下のプロンプトで試してみました。
「DALL-E 3」が生成した画像




「DALL-E 3」が生成した画像の分析
- 画像①:森の中で手にした小さな生き物を観察する女性。アート的な表現が強調され、幻想的な雰囲気が漂います。
- 画像②:緑豊かな森の中を歩く女性の後ろ姿。背後の滝や岩、植物のディテールが鮮明に描写されています。
- 画像③:川辺に座る女性が森を見つめる姿。色彩の美しさや背景のディテールは「DALL-E 3」の強みが感じられます。
- 画像④:山道を歩く女性の後ろ姿。遠くの霧や樹木の光と影の表現が特徴的です。
「Midjourney」が生成した画像




「Midjourney」が生成した画像の分析
- 画像①:女性が山々を背景に静かに目を閉じているシーン。細部にわたるリアルさと、鮮やかな色彩が特徴。
- 画像②:緑豊かな森の中、岩の上でリラックスしている女性。光と影のコントラストが美しく、自然との一体感が感じられます。
- 画像③:川辺に横たわる女性のシルエット。水の反射や女性の表情が非常にリアル。
- 画像④:静かな湖畔で微笑む女性。背景の湖の水面や樹木のリアルさが際立っています。
【総評】「DALL-E 3」と「Midjourney」の生成画像の比較の結果
「DALL-E 3」と「Midjourney」の生成能力を比較してみると、それぞれに得意な領域が明確になりました。
人物のリアリティ
「Midjourney」 で生成された上の4つの画像を見てみると、女性の顔のディテールや肌の質感、髪の質感など、非常に高度なリアリティを持っていることが分かります。特に、川辺でリラックスする女性や、岩場で休む女性の画像は、光の当たり方や影の作り出す立体感が非常にリアルです。
一方、「DALL-E 3」 で生成された下の4つの画像は、背景や環境に関しては非常に詳細かつリアルな表現をしていますが、女性の姿や表情はややアート的で、フォトリアルというよりは絵画のような印象を受けます。
背景の詳細性
「DALL-E 3」 の背景の生成能力は、非常に詳細で豊かです。深い森、滝、川などの自然環境が、鮮やかな色彩とともに細かく表現されています。特に、手前に映る小さな水たまりや、遠くの山々まで、景色の奥行きが非常に感じられるのは、このツールの特徴の一つと言えるでしょう。
対照的に、「Midjourney」は、背景よりも人物に焦点を当てた生成を行っているように見えます。背景も詳細に描かれていますが、特に女性の姿や表情、姿勢などが非常にリアルであり、人物の存在感が強調されています。
このように、「Midjourney」は人物のリアリティが非常に高く、表情や細かなディテールまで非常に精緻に再現されています。一方、「DALL-E 3」は背景の詳細性や独特のアート的な雰囲気を持っています。
「DALL-E 3」と「Midjourney」の活用方法
「DALL-E 3」は、イラストやアートワーク、ファンタジーの世界観を表現したい場面など、芸術的な要素を求めるシーンでの使用が適しています。
「Midjourney」は人物をメインとした広告やポートレート写真、ファッションのビジュアルなど、リアルさを求めるシーンでの使用が推奨されます。
いずれの技術も、その特性を理解し、適切な場面で使用することで、最大の効果を発揮します。
「DALL-E 3」は芸術性を、「Midjourney」は現実感を強調したい場合に選択するとよいでしょう。今後の技術の進化とともに、これらの画像生成能力もさらに向上していくことが期待されます。
【12/5追記】ChatGPT「DALL-E 3」で生成した画像を、動画生成AI「Runway」で動画にする方法
新たに「ChatGPT「DALL-E 3」と動画生成AI「Runway」で実現!画像を動画にする方法」の記事を書きました。
「Runway」は、一言でいうとAIを活用した革新的な画像・動画生成ツールです。「Gen-2」や新機能「Motion Brush」などが発表され、今話題のAIツールです。
そこで、ChatGPT「DALL-E 3」で生成した画像を、「Runway」を使って動画にする方法を詳しく解説しました。
動画を簡単に作りたい方には必見の内容です。
「ChatGPT「DALL-E 3」と動画生成AI「Runway」で実現!画像を動画にする方法」についてはこちらの記事に詳しく解説しています。

【12/16追記】音声機能を使って、「DALL-E 3」を操作することができます

ChatGPT公式アプリの音声機能を使って、画像生成機能(DALL-E 3)を操作することができることが判明しました。
「ChatGPT公式アプリ」についてはこちらの記事に詳しく解説しています。

「DALL-E 3」の利用に際する注意事項と安全性確保に向けた取り組み

OpenAIが開発した「DALL-E 3」は、高度な画像生成技術を持つAIツールです。
「DALL-E 3」の利用に際して、著作権や安全性に関する重要な情報があります。こちらでその詳細について解説します。
1. 著作権に関して
「DALL-E 3」で生成された画像の所有権は、基本的にはユーザーが持っています。これにより、画像の転載や販売、その他の商用利用など、様々な形での利用が許可されています。
ただし、生成内容によっては他の著作権や知的財産権に触れることが考えられるので、十分な注意が必要です。
2. 有害な内容の制限
OpenAIは、「DALL-E 3」の生成能力に対して、暴力的、成人向け、憎悪的な内容の生成を制限しています。これはユーザーの安全を保護し、問題の発生を予防するための措置です。
3. 公的人物の生成についての制限
特定の公的人物や有名人を不適切に利用するリスクを低減するため、「DALL-E 3」では名前を指定した公的人物の生成リクエストが拒否されることがあります。
4. 起源の識別ツールについて
OpenAIは、生成された画像が「DALL-E 3」によって作成されたものであるかを確認するための新しいツール、通称「起源識別器(a provenance classifier)」の導入を検討中です。このツールを使うことで、ユーザーや第三者がAIによって生成された画像を簡単に識別できるようになることを目指しています。
「DALL-E 3」は、上記のような安全性や著作権の取り組みを背景に、多くのユーザーに支持されています。このツールを利用する際には、これらの点を十分に理解し、適切に活用してください。
「DALL-E 3」のよくある質問 (FAQ) とその回答
まとめ

ChatGPTの新機能「DALL-E 3」は、前世代の「DALL-E 2」から飛躍的に進化した画像生成AIで、高解像度の画像を更にリアルに生成します。
さらに、入力されるテキストの意味やニュアンスを深く捉える能力も向上しており、これはDALL-E 3独特の認識アルゴリズムに起因します。
そして驚くべきことに、英語だけでなく日本語のプロンプトでも有効に動作します。特に日本語での画像生成の実力は、他の多くのAI技術とは一線を画すものとなっています。
OpenAIはこの技術の安全な利用を強く推進しており、有害な内容の生成制限や公的人物の生成に関する制約、そして生成画像の起源を特定するツールの導入を進めています。DALL-E 3の進化は単なる技術的なものだけでなく、多岐にわたる表現力と安全性を併せ持つものとなっています。
最後に、ChatGPTの新機能「DALL-E 3」の重要なポイントをまとめます。
ChatGPT 新機能「DALL-E 3」の重要なポイント
- 高解像度の画像生成:DALL-E 3は前世代と比べて高解像度の画像をよりリアルに生成します。
- テキスト忠実度の向上:複雑なテキストでもその意味やニュアンスをしっかりと捉える能力が強化されました。
- 多様な場面での対応:日常のささいな疑問から、業務上の複雑な問題まで、幅広いシチュエーションで適切な情報やアドバイスを提供します。
- 安全性への取り組み:有害な内容の制限、公的人物の生成に関する制約、生成画像の起源を特定するツールなど、ユーザーの安全性を確保するための取り組みが強化されています。
- 商用利用と著作権:生成した画像の商用利用が可能で、OpenAIはAPIを通じてのコンテンツに対する著作権を主張しない立場を取っていますが、利用規約や著作権法上の制約に注意が必要です。
「DALL-E 3」の可能性は無限大です。この技術を手に、あなたも新しいクリエイティブの世界を探索し、未知の表現の領域を開拓してみてはいかがでしょうか。
最先端の技術が、あなたの想像を超えた作品を生み出しますよ!

これまでに紹介したChatGPT 新機能の一覧
ChatGPTは日々進化しており、新機能が頻繁に追加されています。
これらの新機能は、ユーザーの使いやすさを向上させるため、またより多様な用途でChatGPTを活用できるように設計されています。
これまでに紹介した新機能は、定期的に更新される「ChatGPT 新機能の一覧(カテゴリページ)」にて詳しく解説しています。
新機能を効果的に活用することで、ChatGPTの可能性をさらに広げることができます。
新機能のアップデート情報は、当ブログで随時お知らせしていますので、最新の情報をチェックして、ChatGPTの魅力を最大限に活用しましょう!

最後までお読みいただきありがとうございました!









コメント
コメント一覧 (2件)
このブログpostはとても参考になりました!DALL-E 3の日本語対応が手軽に活用できることに感激しています。これから画像生成を試してみるのが楽しみです!
Daman Game Loginさま、コメントありがとうございます!
「DALL-E 3」の日本語対応がご活用いただけて嬉しいです。手軽に画像生成ができるようになり、アイデアを視覚化する楽しさがさらに広がりますよね。ぜひ、いろいろと試してみてください!
今後も役立つ情報を発信していきますので、引き続きブログをチェックしていただけると嬉しいです。